Vào chủ nhật 27/10, hai sự kiện độc lập đã gây ra sự gia tăng về latency và tỷ lệ lỗi cho Cloud DNS kéo dài 40 phút. Trong thời gian đỉnh điểm 20 phút của tác động, chúng tôi thấy rằng 60% yêu cầu DNS đến CloudDNS của latency Time To First Byte (TTFB) tăng gấp 3.5 lần.
Event:
- Hệ thống network monitoring tự đông phát hiện lưu lượng peak cao đột biến và tự động routing traffic không tối ưu giữa 2 region HN – HCM gây ra tình trạng tắc nghẽn vào 20h15 và 20h30
- Một cơ chế giảm thiểu DDOS mới được triển khai trong khoảng thời gian 13:11 và 19:06 đã gây ra 1 bugs ẩn trong module limit tốc độ của Cloud DNS khiến processes xử lý rơi vào vòng lặp vô hạn vào 20h10-20h40
Tác động từ 2 việc trên ảnh hưởng tới 2 cụm region HN – HCM
Đối với event 1: tối ưu lại hệ thống và định tuyến để mitigation
Đối với event 2:
- Là một phần trong việc update thường xuyên cho cơ chế bảo vệ của Cloud CSP, team đã tạo một rules DDoS mới để ngăn chặn một loại phương thức tấn công mới mà team phát hiện trên hạ tầng của mình. Rules DDoS này hoạt động như dự kiến, tuy nhiên trong một trường hợp lưu lượng truy cập peak đột biến, rules đã kích hoạt 1 bugs ẩn trong module limit tốc độ hiện có. Sau khi điều tra team xác nhận lưu lượng peak đột biến không phải cố tình khai thác lỗi.Team rất tiếc về tác động này và đã thực hiện các thay đổi để giúp ngăn chặn những sự cố này xảy ra lần nữa.
Background:
Rate suspicious traffic:
Thông thường, module limit tốc độ này sẽ được áp dụng dựa trên địa chỉ IP của các query DNS. Vì nhiều tổ chức và Nhà cung cấp dịch vụ Internet (ISP) có thể có nhiều thiết bị và người dùng đằng sau một địa chỉ IP duy nhất, nên giới hạn tốc độ dựa trên địa chỉ IP là một phạm vi rộng có thể vô tình chặn lưu lượng truy cập hợp pháp.
Balancing traffic network
CMC CSP có một số hệ thống song song cung cấp khả năng giám sát và cân bằng lại dung lượng theo thời gian thực liên tục để đảm bảo phục vụ nhiều lưu lượng truy cập nhất có thể một cách nhanh chóng và hiệu quả nhất có thể.
Đầu tiên là thuật toán edge load balancer, mọi gói tin đến anycast network của CMC CSP đều đi qua edge load balancer, sau đó edge load balancer sẽ chuyển gói tin đến server thích hợp để xử lý gói tin đó. Server đó có thể ở một vị trí khác so với vị trí ban đầu gói tin network, tùy thuộc vào việc hệ thống tính toán tải. Trong mỗi edge node, mục tiêu là duy trì tải CPU đồng đều trên tất cả các server đang hoạt động.
Trên tất cả các node của Cloud CSP, nó tiếp nhận nhiều signals khác nhau, chẳng hạn như CPU usage, DNS request latency, HTTP request..etc và mức sử dụng băng thông để ra các quyết định cân bằng tải. Nó có các giới hạn để ngăn chặn việc gây ra sự thay đổi lưu lượng quá mức và tải dự kiến tại các vị trí đích khi đưa ra bất kỳ quyết định nào.
Incident timeline and impact
All timestamps UTC+7
- 13:11 DDoS rule deployment
- 19:06 DDoS rule deployed
- 19:58 First DNS request Peak handling
- 20:01 Incident declared automatically based high CPU load
- 20:08 Service restart shown to recover on a server, full restart tested in one cluster node
- 20:10 CPU load normalized in cluster after service restart
- 20:12 Continual reloads of all servers with many stuck processes begin
- 20:14 DNS error rate peaks at 60%
- 20:16 First automation actions
- 20:20 error rate halved to 40%
- 20:31 error rate reduced to baseline levels
- 20:38 DDoS rule deployment identified as likely cause of process poisoning
- 20:40 DDoS rule is fully disabled
- 20:43 Engineers stop routine restarts of services on servers with many stuck processes
- 21:01 Incident response stood down
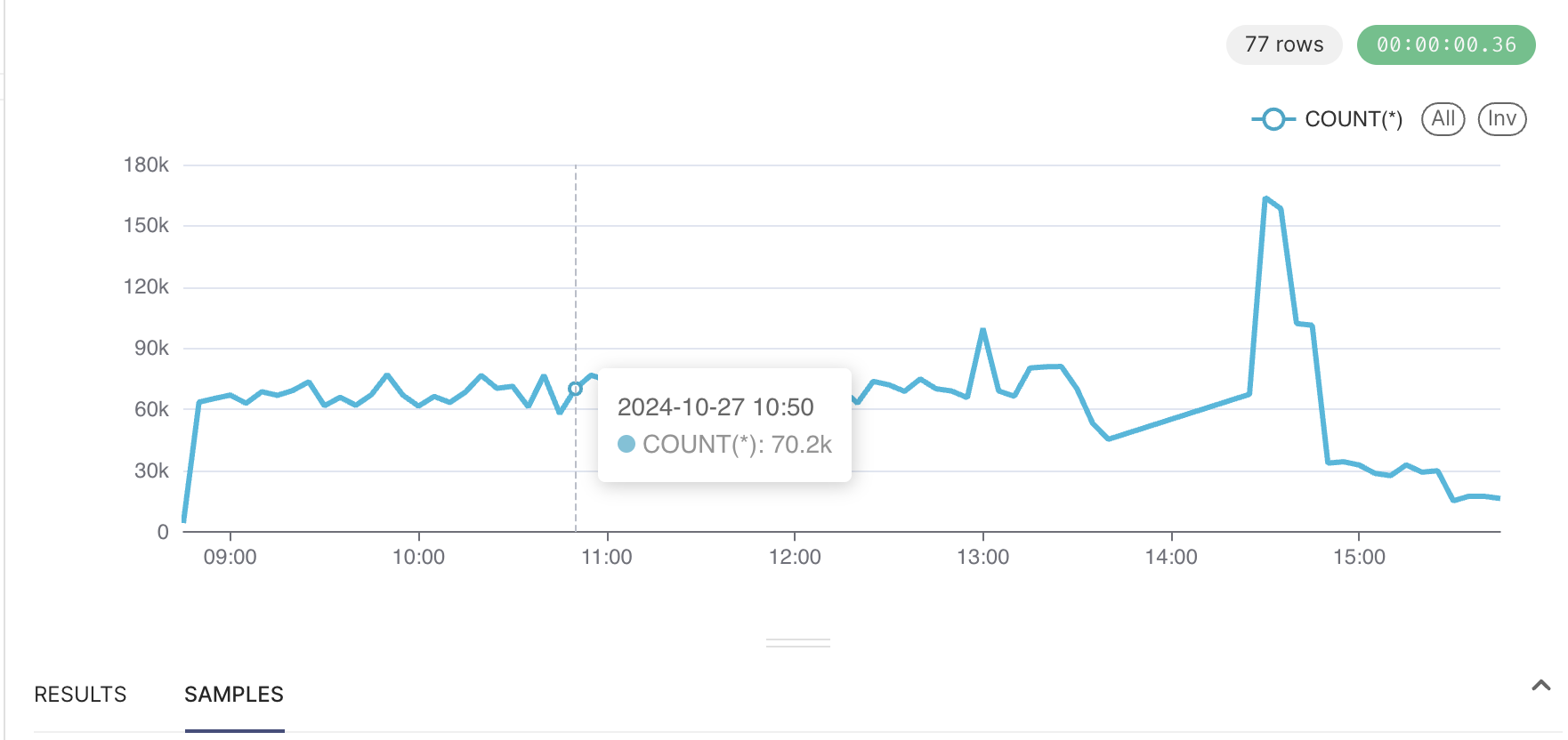
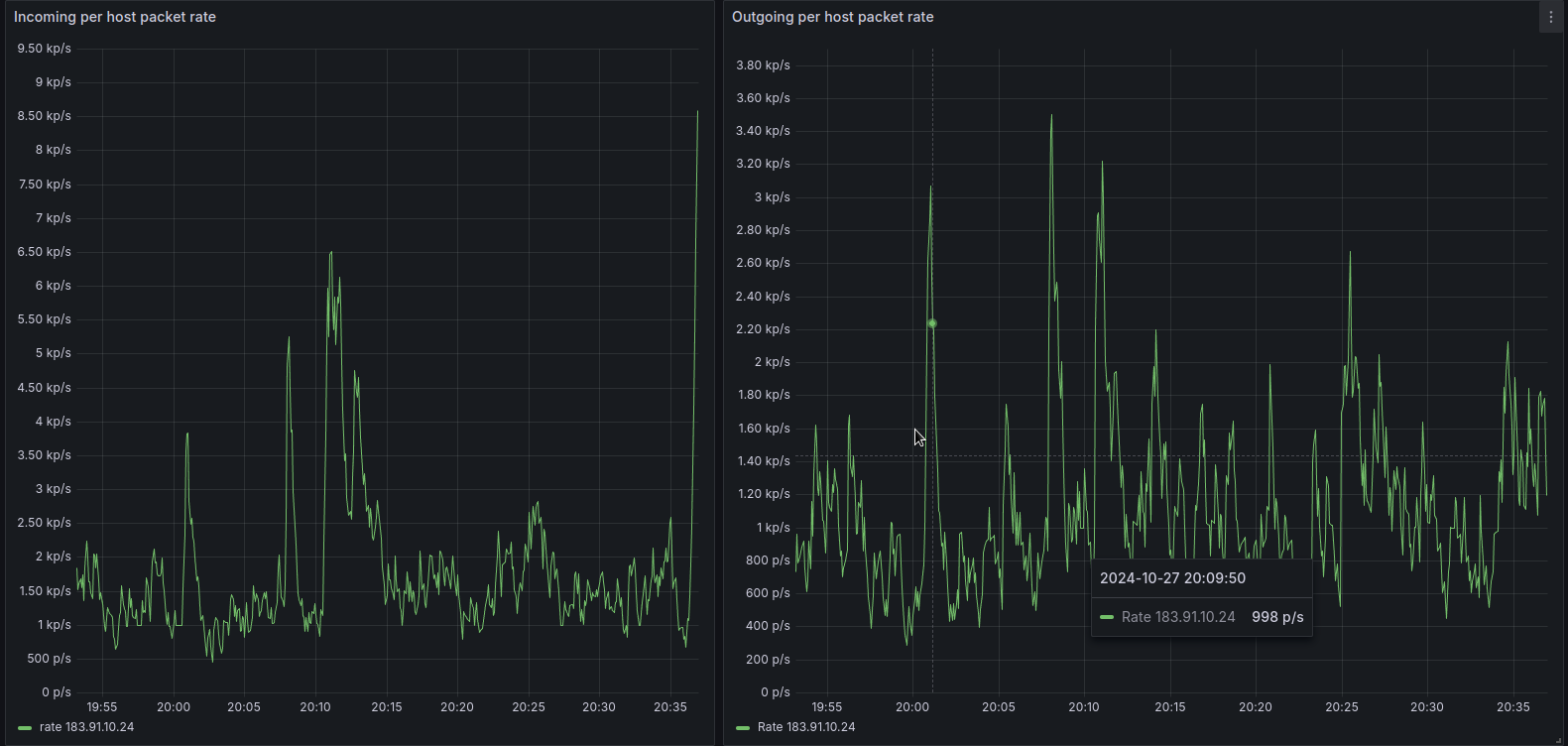
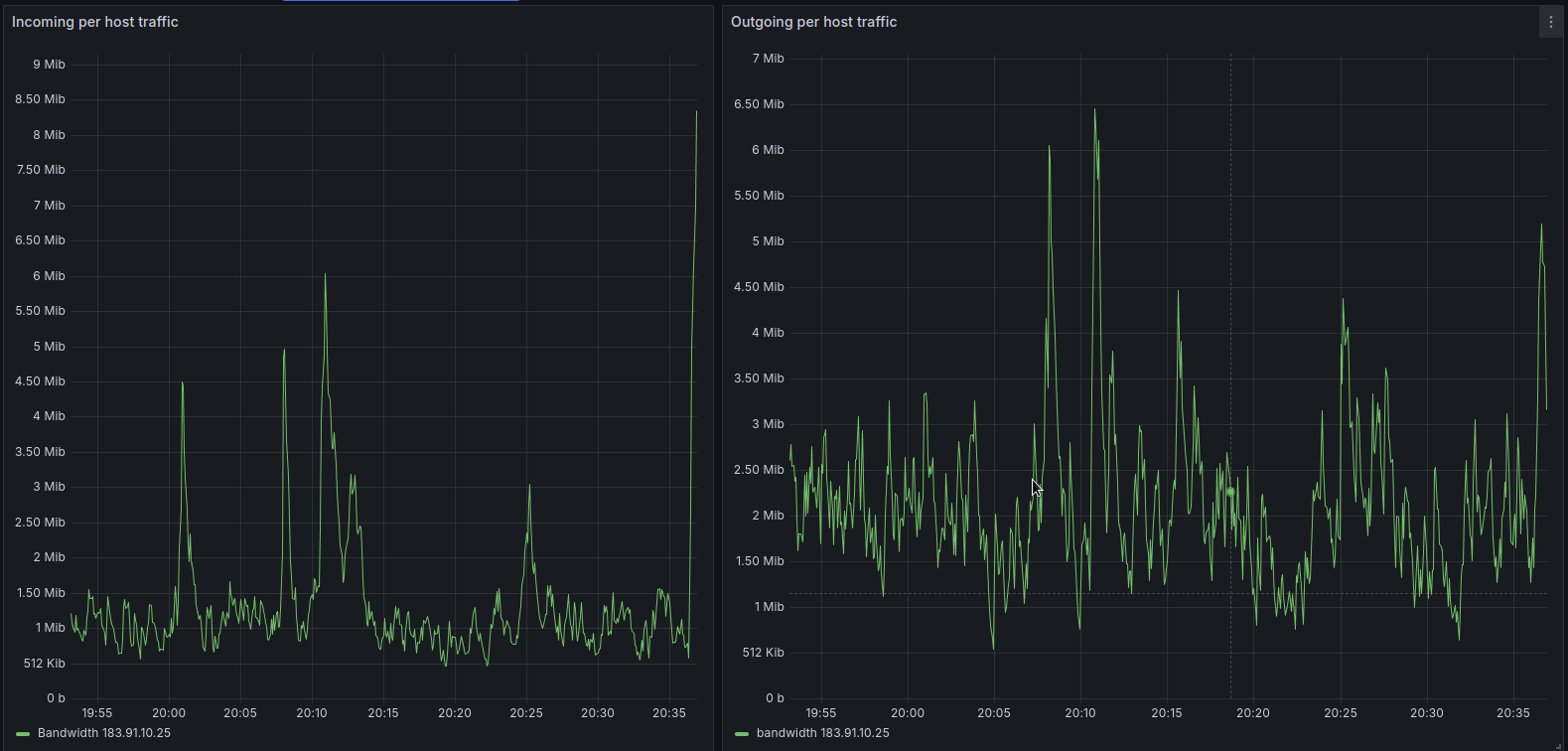
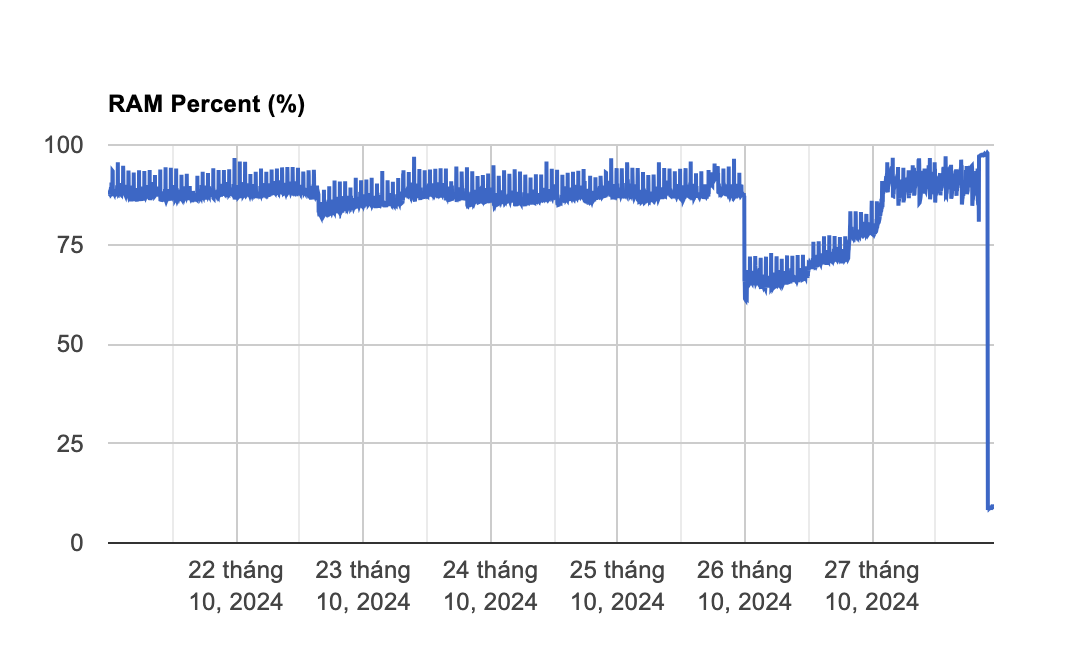
Tỷ lệ của các processes xử lý DNS request đang sử dụng quá nhiều CPU/Ram trong sự kiện
27/10, trong khoảng thời gian từ 13:11 – 19:06 UTC+7, hệ thống đã dần kích hoạt một rules DDoS mới trên hệ thống network của CMC CSP. Phương pháp này sử dụng kết hợp giữa limit tỷ lệ và query DNS để cho phép các client hợp pháp bị xác định false positive là một phần của cuộc tấn công vẫn có thể tiếp tục truy vấn.
Với phương pháp này, một yêu cầu DNS được coi là đáng ngờ sẽ chạy qua các bước chính sau:
- Kiểm tra xem có request DNS hợp lệ hay không, nếu không, block request
- Nếu tìm thấy request hợp lệ, thêm quy tắc giới hạn tỷ lệ dựa trên giá trị request để đánh giá sau
- Sau khi chạy tất cả các biện pháp giảm thiểu DDoS hiện đang áp dụng, áp dụng các quy tắc giới hạn tỷ lệ
- CMC CSP sử dụng processes làm việc “không đồng bộ” này vì việc chặn request mà không có quy tắc giới hạn tỷ lệ sẽ hiệu quả hơn, do đó, nó tạo cơ hội cho các loại quy tắc khác được áp dụng.
- Khi đánh giá các quy tắc giới hạn tỷ lệ, 1 mã khóa được tạo ra cho mỗi máy khách được sử dụng để tra counter chính xác và so sánh với tỷ lệ mục tiêu. Thông thường, khóa này là địa chỉ IP của máy khách, nhưng có các tùy chọn khác, chẳng hạn như giá trị của request DNS như được sử dụng ở đây.
Hàm tạo khóa có hai vấn đề, kết hợp với một dạng request cụ thể của client, gây ra vòng lặp vô hạn trong quá trình xử lý yêu cầu DNS:
Các quy tắc giới hạn tỷ lệ do logic DDoS tạo ra đang sử dụng API nội bộ theo 1 cách sai logic. Điều này khiến key_generator trong code trỏ đến chính hàm get_request, nghĩa là nếu code đó được kích hoạt, hàm sẽ tự gọi vô thời hạn
Một biện pháp bảo vệ mà nhiều ngôn ngữ lập trình áp dụng để giúp ngăn chặn các vòng lặp như thế này là giới hạn bảo vệ thời gian chạy đối với độ sâu của stack các lệnh gọi hàm. Việc cố gắng gọi một hàm một lần ở giới hạn này sẽ dẫn đến lỗi thời gian chạy. Khi đọc logic ở trên, một phân tích ban đầu có thể cho thấy nó đã đạt đến giới hạn trong trường hợp này và do đó các yêu cầu cuối cùng dẫn đến lỗi, với stack chứa các lệnh gọi hàm đó nhiều lần.
Kết quả cuối cùng là một vòng lặp trong logic xử lý yêu cầu không bao giờ làm tăng kích thước của stack. Thay vào đó, nó chỉ đơn giản là tiêu thụ 100% tài nguyên CPU khả dụng và không bao giờ kết thúc. Khi một processes xử lý các yêu cầu DNS nhận được một yêu cầu duy nhất mà hành động nên được áp dụng và có sự kết hợp giữa request hợp lệ và không hợp lệ, processes đó bị lỗi và không bao giờ có thể xử lý bất kỳ yêu cầu nào nữa.
Việc tăng mức sử dụng CPU cho server khiến hệ thống tự động giảm lượng lưu lượng truy cập mới mà server nhận được, chuyển lưu lượng truy cập đến các server khác, do đó, tại một thời điểm nhất định, nhiều kết nối mới được chuyển hướng khỏi các server có một tập hợp con các processes bị nhiễm độc sang các server có ít hoặc không có processes bị lỗi, do đó, mức sử dụng CPU thấp hơn.
Việc tăng dần mức sử dụng CPU trong server bắt đầu khiến hệ thống chuyển hướng lưu lượng truy cập đến các server khác. Vì động thái này không khắc phục được các processes bị lỗi, nên mức sử dụng CPU vẫn ở mức cao, do đó hệ thống tiếp tục chuyển hướng ngày càng nhiều lưu lượng truy cập đi.
Lưu lượng truy cập được chuyển hướng trong cả hai trường hợp bao gồm các yêu cầu là processes bị lỗi, khiến các server mà lưu lượng truy cập được chuyển hướng này được gửi đến bắt đầu gặp sự cố theo cùng một cách
Trong vòng vài phút, nhiều server đã có nhiều process lỗi và hệ thống đã chuyển hướng càng nhiều lưu lượng truy cập khỏi các server này càng tốt, nhưng bị hạn chế không thể làm nhiều hơn nữa. Một phần là do giới hạn an toàn tự động hóa tích hợp của nó, nhưng cũng vì ngày càng khó tìm được một server có đủ dung lượng khả dụng để sử dụng làm mục tiêu.
Các server bj lỗi một phần ở nhiều vị trí đã phải vật lộn với các request và các process còn lại không thể theo kịp, dẫn đến việc lỗi toàn cục
Team đã nhận được thông báo tự động vào 19:40 sau khi mức sử dụng CPU các server đạt đến một mức duy trì nhất định và bắt đầu điều tra. Phải mất một thời gian, team mới nhận ra rằng các server có CPU cao nhất là nơi có lưu lượng truy cập thấp nhất, khiến cuộc điều tra không còn tập trung vào sự kiện network. Tại thời điểm này, trọng tâm chuyển sang hai luồng chính:
- Đánh giá xem việc khởi động lại các process lỗi có cho phép chúng phục hồi hay không và nếu có, kích hoạt khởi động lại hàng loạt dịch vụ trên các máy chủ bị ảnh hưởng
- Xác minh vấn đề gây CPU cao
25 phút sau khi sự cố ban đầu được phát hiện, team đã xác thực rằng việc khởi động lại có hiệu quả trên một máy chủ mẫu. Năm phút sau đó, team bắt đầu thực hiện khởi động lại rộng hơn – ban đầu là toàn bộ các edge node cùng một lúc, sau đó khi phương pháp xác định được tinh chỉnh, trên các server có process lỗi. Một số nhân sự tiếp tục khởi động lại dịch vụ bị ảnh hưởng theo định kỳ trên các server bị ảnh hưởng, trong khi những người khác chuyển sang tham gia nỗ lực song song đang diễn ra để xác định sự cố. Vào lúc 21:01, rules DDoS mới đã bị vô hiệu hóa trên toàn bộ node và sự cố đã được giải quyết sau khi thực hiện thêm một vòng khởi động lại hàng loạt và giám sát.
Đồng thời, các điều kiện do sự cố gây ra đã kích hoạt một lỗi ẩn trong module traffic limit đã được fix.
Các bước khắc phục và theo dõi:
Để giải quyết tác động tức thời đến network của hệ thống, Team đã khởi động lại hàng loạt dịch vụ bị ảnh hưởng cho đến khi thay đổi kích hoạt tình trạng được xác định và khôi phục. Thay đổi, là kích hoạt một loại rules DDoS mới, vẫn được khôi phục hoàn toàn và rules sẽ không được kích hoạt lại cho đến khi khắc phục được lỗi và hoàn toàn tin tưởng rằng tình huống này không thể tái diễn.
Team sẽ tiếp tục cải thiện các quy trình testing và triển khai của mình để giảm thiểu sự việc liên quan đến thay đổi tiềm ẩn.



